
在先前的文章中,我們討論了 Uptime Kuma 這個優秀的開源工具,它能幫助我們監控網站、API 服務和資料庫的存活狀態。透過定期的訪問檢查,Uptime Kuma 能夠即時顯示服務是否在線且可訪問。然而,實務中僅僅依賴服務的可用性指標是不夠的。知道一個服務“活著”並不一定意味著它能夠正常運作。
例如以下這種情況:一個 API 服務在回應外部請求時,回應時間和狀態碼都顯示正常,但到後端與資料庫交互時,當系統讀取到某一特定區塊時卻會引發錯誤。在這種情況下,像 Uptime Kuma 這樣的監控工具可能會誤判服務狀態,認為一切正常,沒能有效揭示背後硬體或軟體的潛在問題。
這種 “假存活” 的現象,讓表面上看服務是可用的,系統也沒有發出任何警報,這種 “活著” 的狀態讓我們忽略了可能的潛在問題,在關鍵時刻往往會引發嚴重的後果。
我們在實務中,需要的不僅僅是關注 Uptime Kuma 提供的健康狀況資訊,而是要進行更深層次的檢查,獲取更全面的資訊。透過 Backstage,我們可以輕鬆地將各種監控資訊整合在一起,並搭配其他優秀的工具來滿足我們的需求,而無需從頭開發。
在這樣的架構下,我們可以利用 Grafana 搭配 Prometheus 來掌握更全面的資訊,透過 Prometheus 收集硬體數據、分析 API 的執行時間、每日的請求數量等等,最後將這些數據通過 Grafana 以美觀的圖表形式呈現。
以這樣的監控策略,不論是在日常維護還是即時除錯中,我們通過 Backstage 整合的資訊和不同監控工具的交叉比對,更能夠準確地掌握系統的實際狀況,從而減少潛在風險,或快速找出關鍵的錯誤資訊。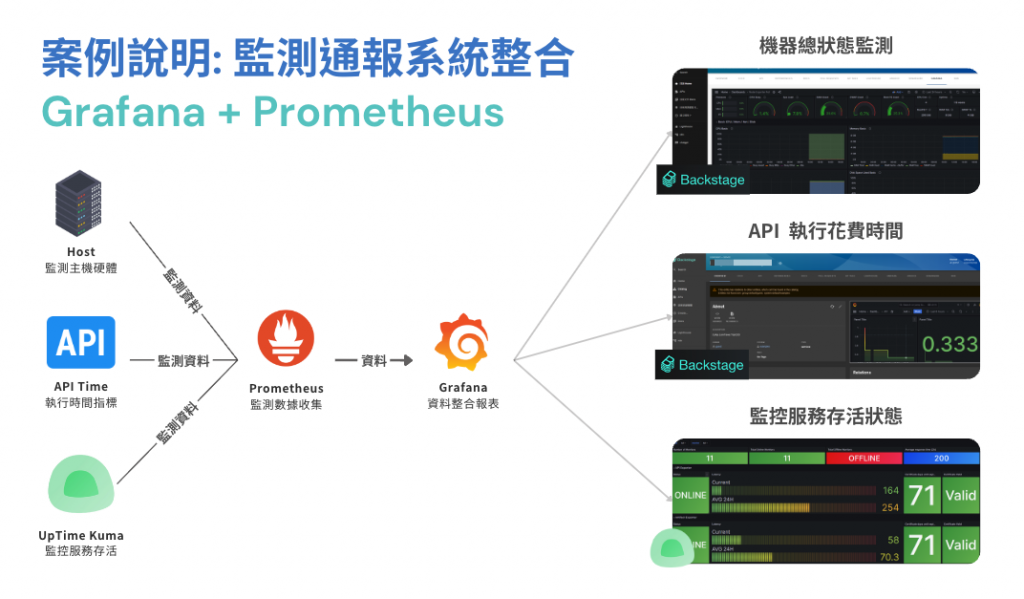
在我們的監控架構中,Grafana 扮演非常重要的角色。作為一個開源的數據圖性化工具,Grafana 能夠從多種數據來源中整合訊息,並將冰冷的數據轉化為動態、直觀的圖表和儀表板。這些圖表不僅美觀,而且功能強大靈活,能幫助我們迅速了解系統的運行狀況。
Grafana 的優勢之一在於它的廣泛性。它支持多種數據源,包括 Prometheus、Elasticsearch、Graphite 以及 SqlServer 等等數不清的應用,我們能夠從各種不同的監控工具中取得數據,並整合在同一個面板中顯示,與 Backstage 的專案頁資訊相似,整合數總平台如下圖的概念。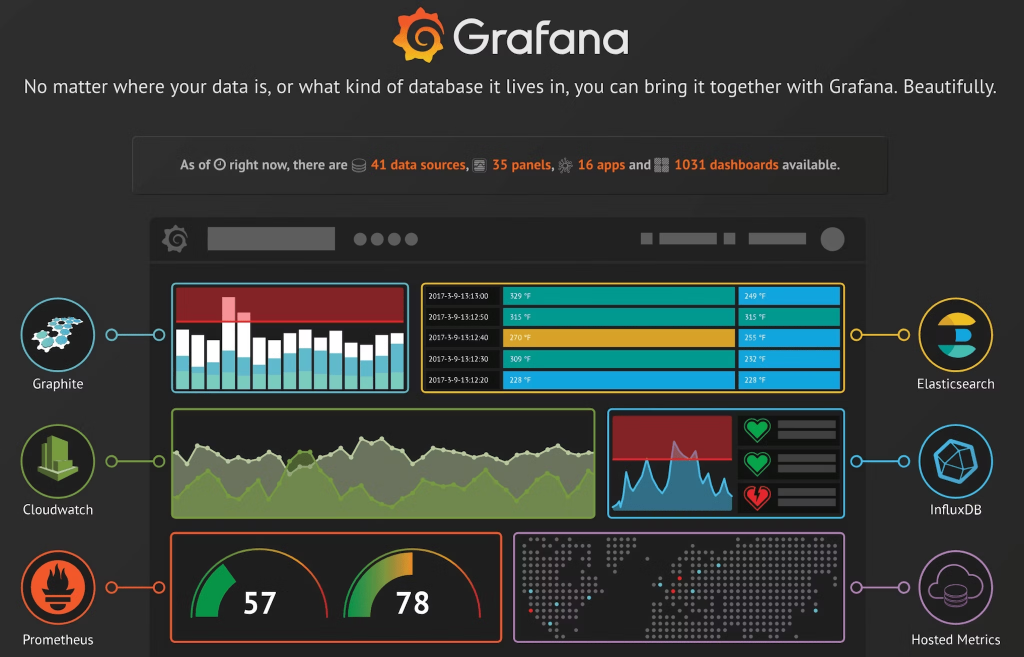
在應用 Grafana 上可以讓我們根據需求來儀表板,例如:為了更好得知硬碟與網路的讀取用量,與 API 平均執行時間之間的關聯,我們將資訊的儀表板放到 Backstage 指定的專案底下,每當我們在 Backstage 查看專案時,都能一眼檢視目前服務的健康狀態,做到儘早預防,即時發現問題的效果。
Grafana 還支援設定警報(Alerting)功能。當監控數據達到設定的限制時,Grafana 會自動發出警報通知,幫助我們快速反應,並且支援如 Line Notify、Email 通知等等。
並且在官網上還有各式各樣的模板可以直接使用,皆來自不同社群使用者上傳提供。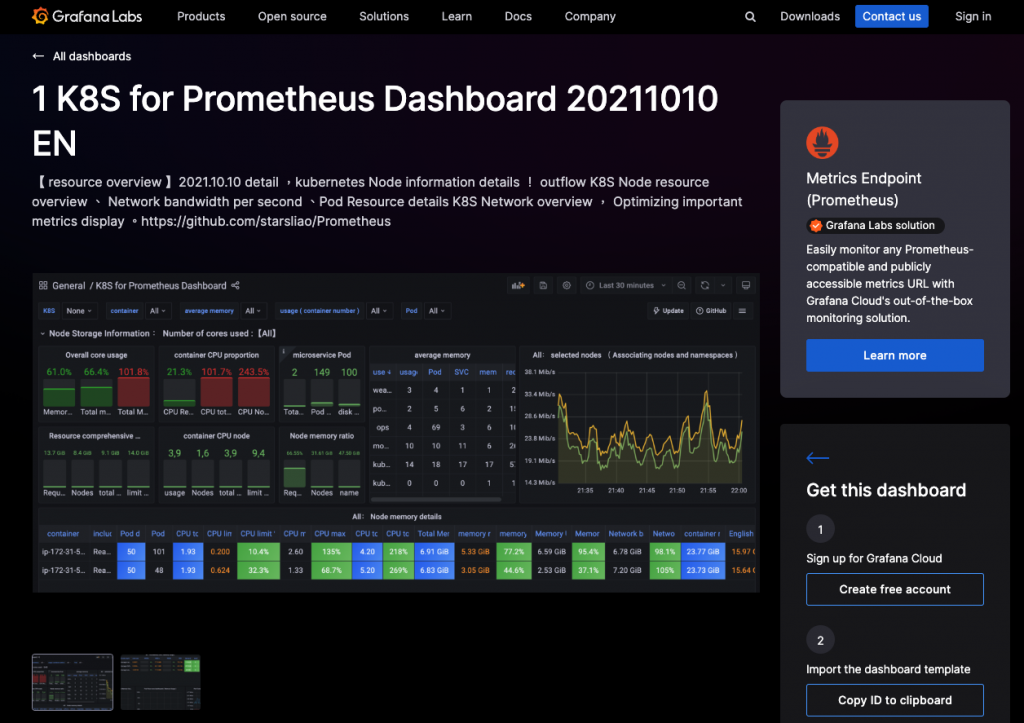
每當提到以圖形化面板聞名的 Grafana,必然會提到 Prometheus 這個開源的監控系統。作為一個專為分佈式系統設計的時間序列資料庫,Prometheus 在監控需求的處理上表現出色。每個數據點都與時間戳和標籤(labels)相關聯,使得它能夠高效地處理和查詢大量監控數據。這種數據模型不僅提升了數據處理效率,還簡化了複雜查詢的操作。
Prometheus 的查詢語言 PromQL(Prometheus Query Language)是一大亮點,採用結構化語法,具備高度靈活性,並提供豐富的統計函數。這使得用戶能夠快速查詢時間序列數據,輕鬆進行各種數學運算和統計分析,特別適合分析特定時間段的資訊。
Prometheus 採用 metrics pull 模式來收集監控數據,這意味著 Prometheus 會定期主動從被監控的服務中抓取數據,而不是由服務主動推送數據。這種方式的優勢在於,Prometheus 可以集中控制數據收集的頻率和方式,從而更好地統一管理和優化監控資源的使用。
另外與 Grafana 相同,Prometheus 也支持警報功能,兩者可以根據需求選擇和搭配使用。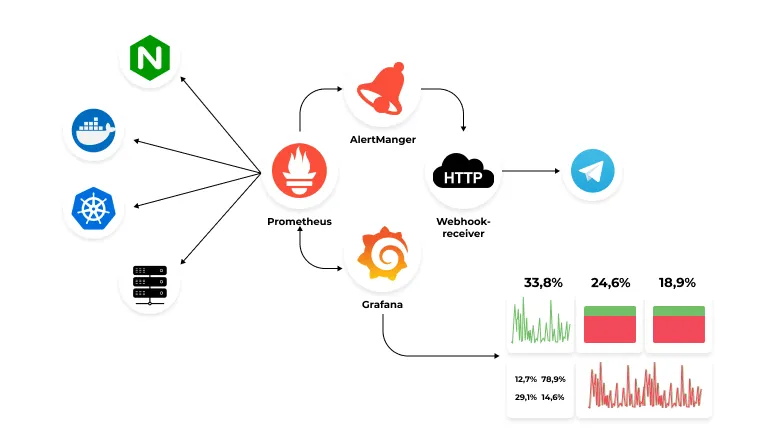
Grafana 常見搭配 Prometheus 的使用模式 / 圖片來源 - https://doubletapp.medium.com/overview-of-monitoring-system-with-prometheus-and-grafana-9ce6501eff88
以收集機器硬體的資訊為範例,我們需要安裝 Prometheus Exporter 模組,這邊連同 Grafana、Prometheus 的設定檔也一併附上。
grafana 需注意環境設定的部分,允許跨域的嵌入頁面也允許匿名訪問,才能正常將 Grafana 儀表板嵌入到 Backstage 中。
prometheus 則是在於設定檔中的 prometheus.yaml ,指定要抓取資料來源的服務位置,設定參考可看到下方圖片。
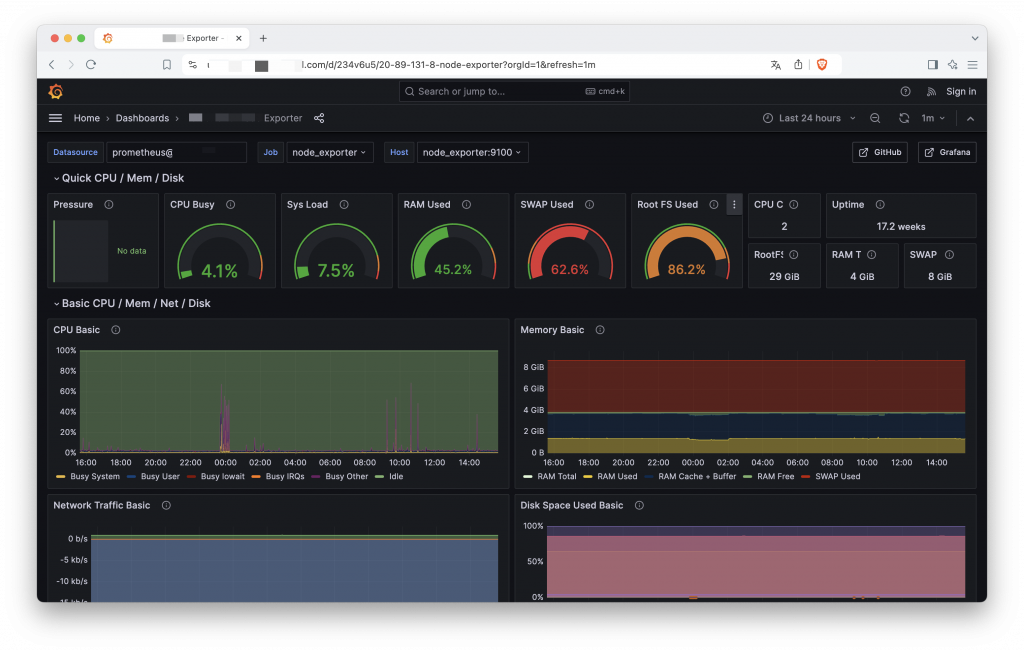
node_exporter 則是我們首先要提到的範例,了解兩者服務之前是如何搭配,並且透過儀表板模板使得我們不需要自行攥寫查詢式。
grafana:
image: grafana/grafana-enterprise
container_name: grafana
restart: unless-stopped
ports:
- '3000:3000'
volumes:
- 'grafana_storage:/var/lib/grafana'
environment:
- GF_SECURITY_ALLOW_EMBEDDING=true
- GF_SECURITY_COOKIE_SAMESITE=none
- GF_SECURITY_COOKIE_SECURE=true
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_AUTH_ANONYMOUS_ORG_NAME=YourORG
- GF_AUTH_ANONYMOUS_ORG_ROLE=Viewer
networks:
- app-network
prometheus:
image: prom/prometheus
container_name: prometheus
restart: always
volumes:
- ./prometheus_data/prometheus.yaml:/etc/prometheus/prometheus.yaml
- ./prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yaml'
- '--web.enable-admin-api'
ports:
- '9090:9090'
networks:
- app-network
node_exporter:
image: prom/node-exporter
container_name: node_exporter
restart: always
volumes:
- '/:/host:ro,rslave'
command:
- '--path.rootfs=/host'
ports:
- '9100:9100'
networks:
- app-network
連結 docker 中的其他服務,若有成功抓到資料就會正常顯示在 Targets 的端點清單中。
// prometheus.yaml
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['prometheus:9090']
- job_name: 'node_exporter'
scrape_interval: 30s
static_configs:
- targets: ['node_exporter:9100']
- job_name: 'uptime_kuma'
scrape_interval: 30s
static_configs:
- targets: ['kuma:3001']
basic_auth:
password: uk2_d4Uv6uoLrM8UobGibN9E7I8iYKZmwyIxxxx
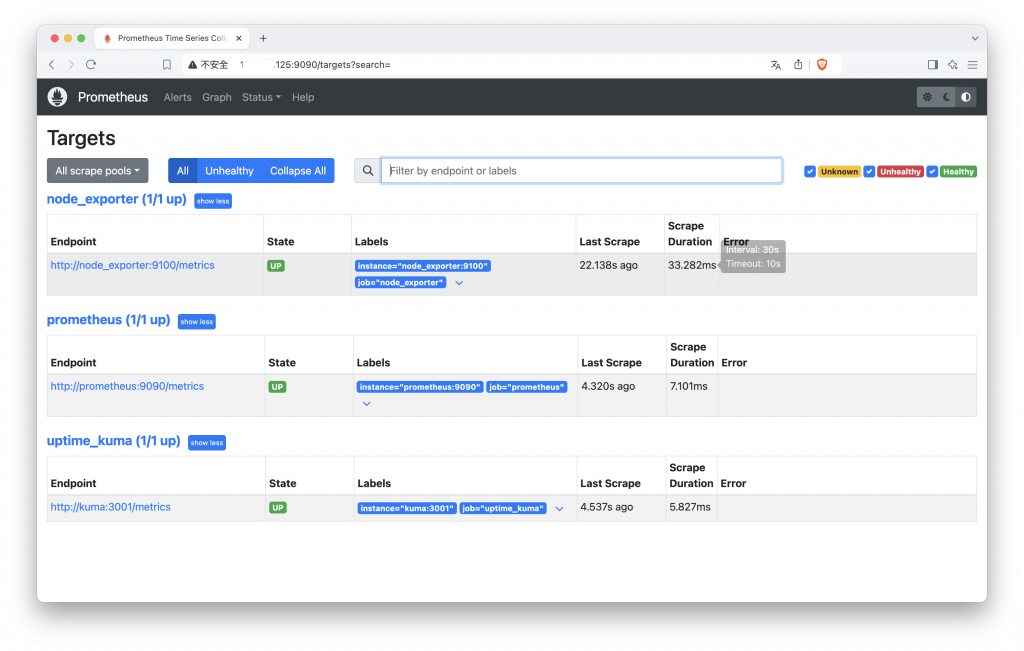
在啟動此服務後它便會自動獲取機器硬體的數據,可以依稀知道它抓取了哪些硬體的資料,顯示出一些使 Prometheus 運算式的數據結果,但是這樣的呈現模式我們完全無法閱讀出任何意義。接下來就是靠 Grafana 來改變數據的模樣了。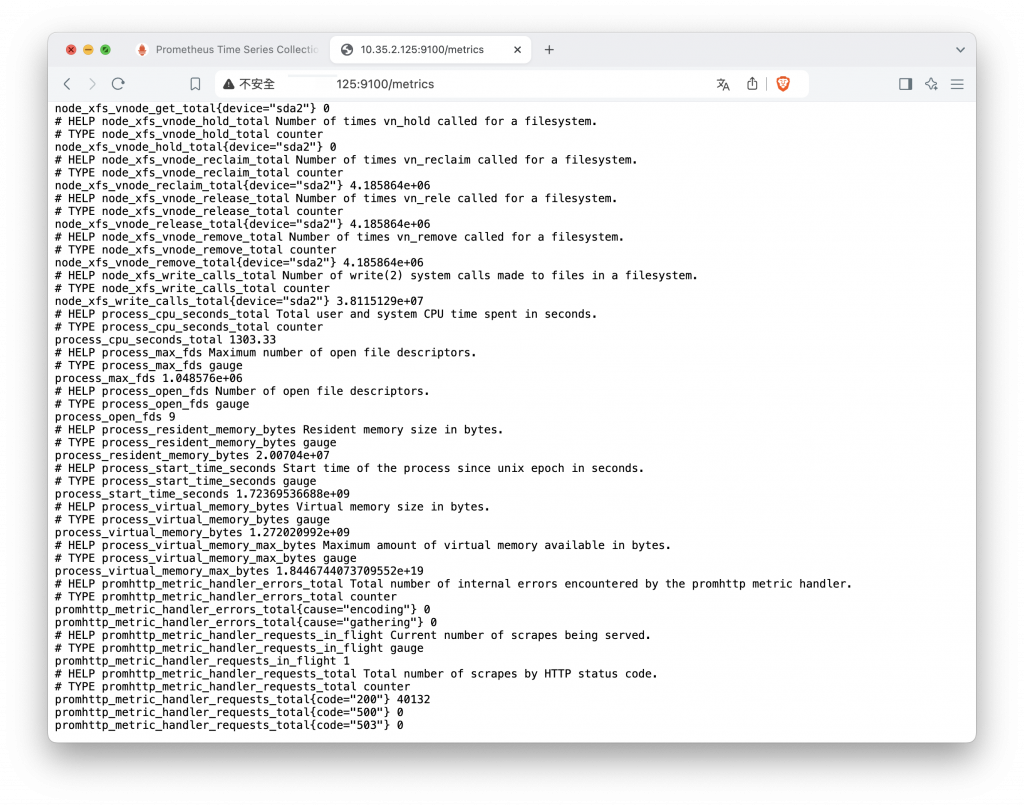
例如我們選用這個 Ndoe Explorer 的專屬模板來匯入 Grafana 使用,我們只需選擇複製模板 ID 或下載 Json 格式檔。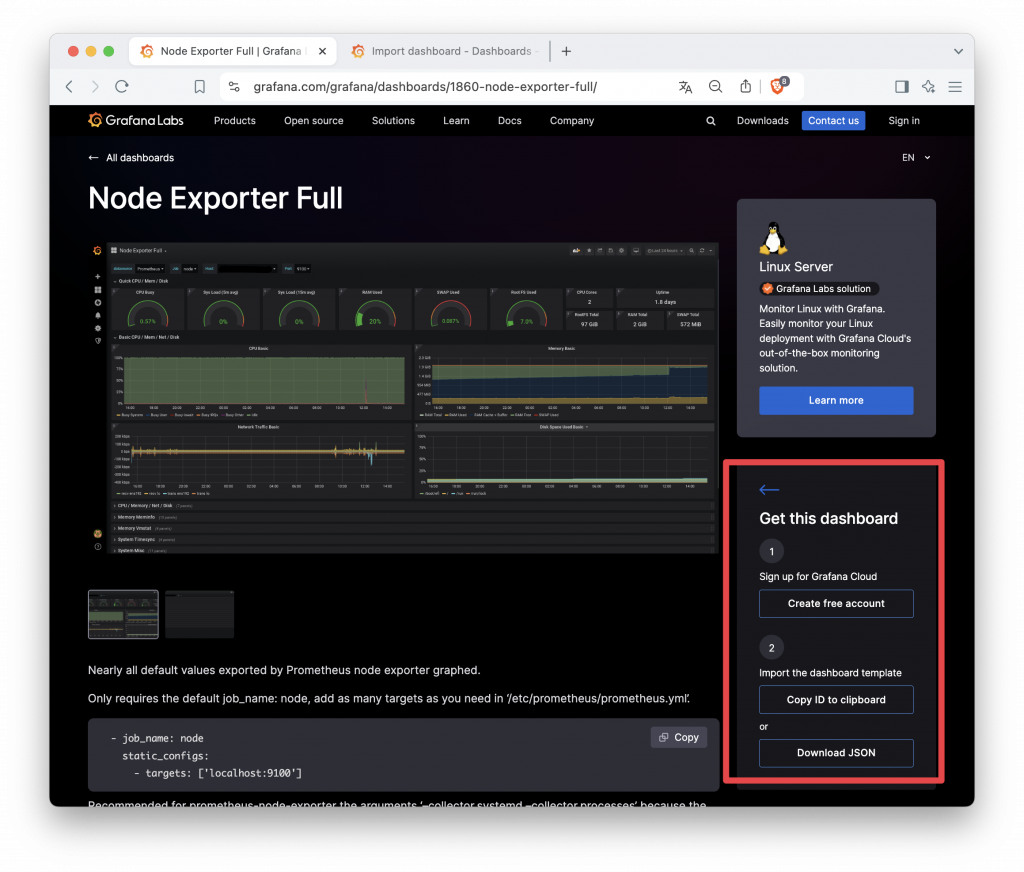
在新增儀表板時匯入現有模板,填入 ID 或 Json 資料。就能將剛剛的文字資訊全部都轉成圖形化的報表囉,當然我們也可以自行撰寫查詢式為模板增加不同的報表,針對機器硬體的資訊,我們直接使用別人做好的模板是最方便。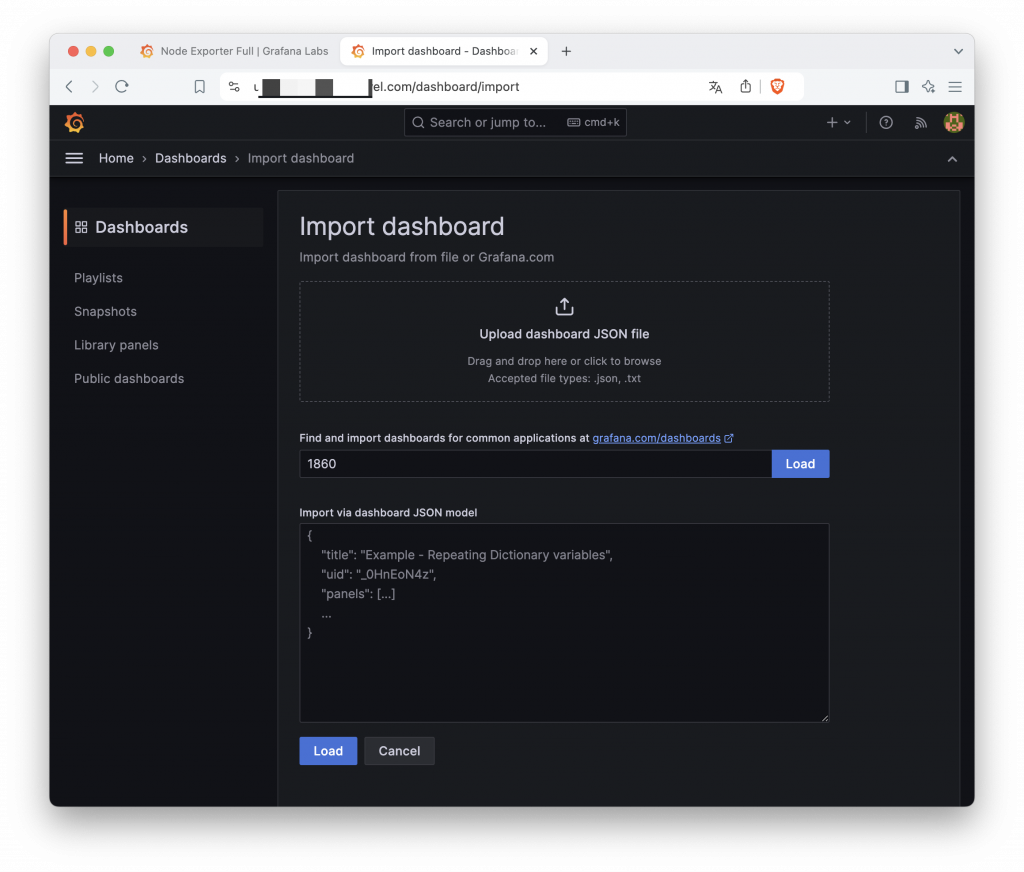
如果覺得 Uptime Kuma 原先的狀態頁資訊呈現的不夠好,也有人在 Grafana 做好專屬它的模板,方便我們可以再拿去根其他資料合併在儀表中。故有了封面的架構圖也把 Uptime Kuma 規劃進去我們的監控系統插件中。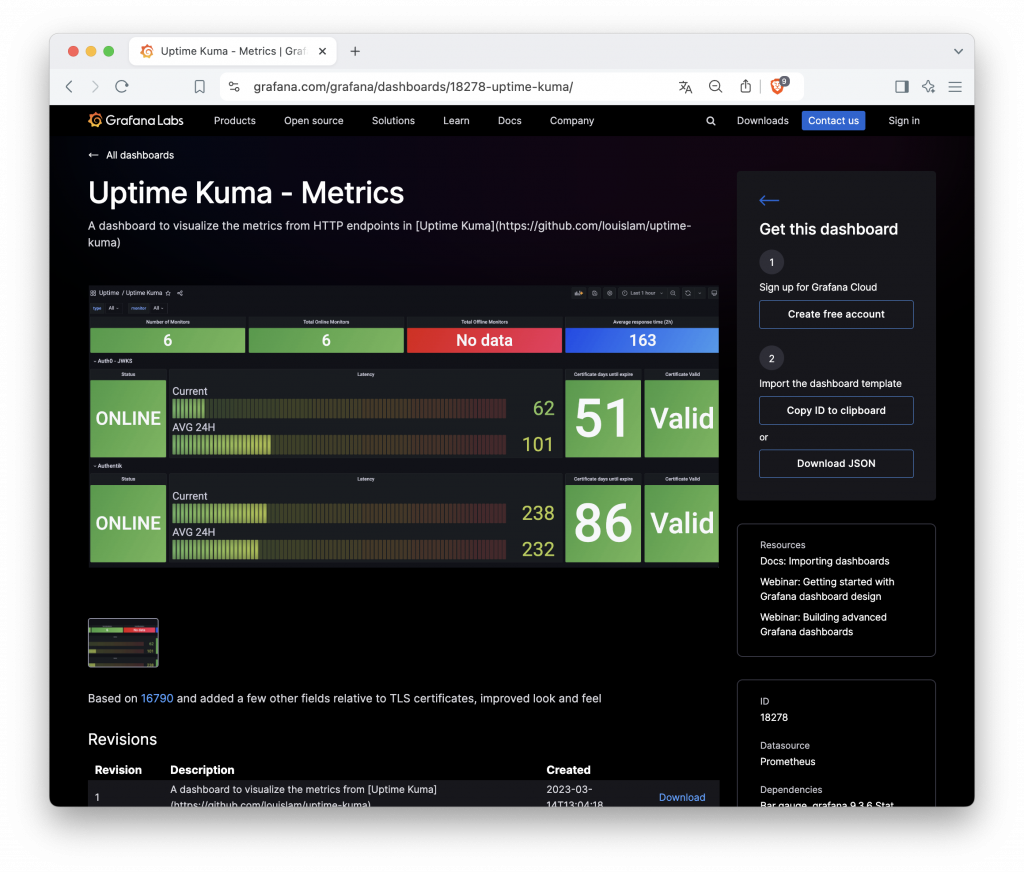
若需要針對不同系統、不同架構下,自訂統計數據的內容,Prometheus 在多數主流語言都有支援套件包,以下為 PHP 和 .NET Core 的範例,兩個程式碼中都設定計數器的統計方式,當我們訪問頁面時 Prometheus 就紀錄一次,http_requests_total 會是查詢的參數,例如說可以算出 http_requests_total / 1 小時平均次數的概念。
使用 promphp/prometheus_client_php 套件來收集 HTTP 請求計數:
<?php
require 'vendor/autoload.php';
use Prometheus\CollectorRegistry;
use Prometheus\RenderTextFormat;
use Prometheus\Storage\InMemory;
$registry = new CollectorRegistry(new InMemory());
$counter = $registry->getOrRegisterCounter('app', 'http_requests_total', '註解', ['method']);
$counter->inc(['GET']); // 計數器增加
header('Content-type: text/plain');
echo (new RenderTextFormat())->render($registry->getMetricFamilySamples());
使用 prometheus-net 套件來收集 HTTP 請求計數:
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.DependencyInjection;
using Prometheus;
public class Startup
{
public void ConfigureServices(IServiceCollection services) => services.AddControllers();
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
app.UseRouting();
app.UseHttpMetrics(); // 啟用 Metrics
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
endpoints.MapMetrics(); // Prometheus 端點
});
}
}
public class MyController : ControllerBase
{
private static readonly Counter RequestsCounter = Metrics.CreateCounter("http_requests_total", "註解");
[HttpGet("/home")]
public IActionResult GetHome()
{
RequestsCounter.Inc(); // 計數器增加
return Ok("Home Page");
}
}
另外在 Prometheus 中,常用的統計方法包括計數器(Counter)、儀表(Gauge)、直方圖(Histogram)和摘要(Summary)。這些方法各有用途,適合不同的監控需求。以下是簡單介紹暫不進一步介紹,撰寫前需要先研究一下:
計數器(Counter)
計數器是一種只增不減的指標,適用於累積性計數,例如記錄總請求數、錯誤數或已處理的任務數。
儀表(Gauge)
儀表是可以增減的指標,適合測量當前狀態的數據,例如記錄系統當前的內存使用量或隊列長度。
直方圖(Histogram)
直方圖用於觀察數據分佈情況,特別適合度量事件的頻率分佈,例如請求延遲的分佈情況。它會將數據分桶(bucket),每個桶表示一個範圍內的數據數量。
摘要(Summary)
摘要也是用來觀察數據分佈的,但與直方圖不同,摘要會直接計算出特定百分位(如 95%、99%)的數值,並提供總計數和總和。
服務啟用後預設給 Prometheus Pull 資料的路徑會是 https://server/metrics 下,首先修改 prometheus.yaml 讓 Prometheus 可以偵測到服務後,再進入 Grafana 連結到 Prometheus,新增儀表板並指定資料來源時,我們可以自行新增 PromQL 查詢產生報表,以下為範例示意圖。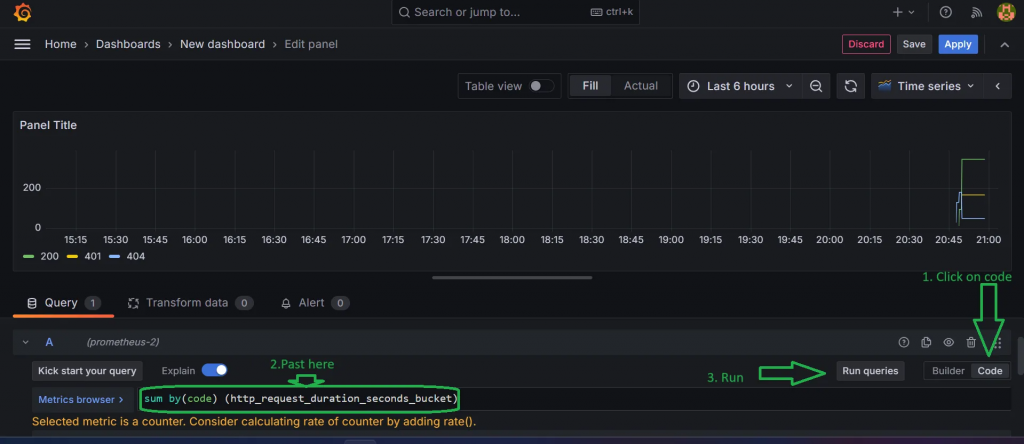
圖片來源 - https://medium.com/@faulycoelho/net-8-api-with-prometheus-and-grafana-29003adafd43
建立好 Grafana 的儀表板後,我們接著要把收集好的數據整合到 Backstage 之中,對於 Grafana Backstage 已經有現成的插件可以使用。
GitHub - K-Phoen/backstage-plugin-grafana: Grafana plugin for Backstage
在安裝後加入 app-config.yaml 的設定,其中在 proxy 的設定,讓我們不必再額外使用後端插件使用憑證去呼叫 Grafana 的 API,反而可以透過前端並且在隱藏憑證的情形下完成。
cd packages/app && yarn add @k-phoen/backstage-plugin-grafana
# app-config.yaml
proxy:
'/grafana/api':
target: https://grafana.host/
headers:
Authorization: Bearer ${GRAFANA_TOKEN}
grafana:
domain: https://grafana.host
unifiedAlerting: false
由於需要 API 的部分是原作者做的儀表板列表的功能,有點像是捷徑的功能,但對我們來說實際需要的是將儀表板直接顯示到 Backstage 中,最後只有使用到插件的 EntityOverviewDashboardViewer 組件,呈現效果其實與我們先前撰寫的 iframe 看起來是差不多的。以下是我加入 EntityPage.tsx 將儀表板顯示在專案主頁的設定。
<EntitySwitch>
<EntitySwitch.Case if={isOverviewDashboardAvailable}>
<Grid item md={12}xs={12} style={{ height: '500px' }}>
<EntityOverviewDashboardViewer/>
</Grid>
</EntitySwitch.Case>
</EntitySwitch>
annotations:
grafana/overview-dashboard: https://xxx.com/d/rYdddlPWk/node-exporter-ful
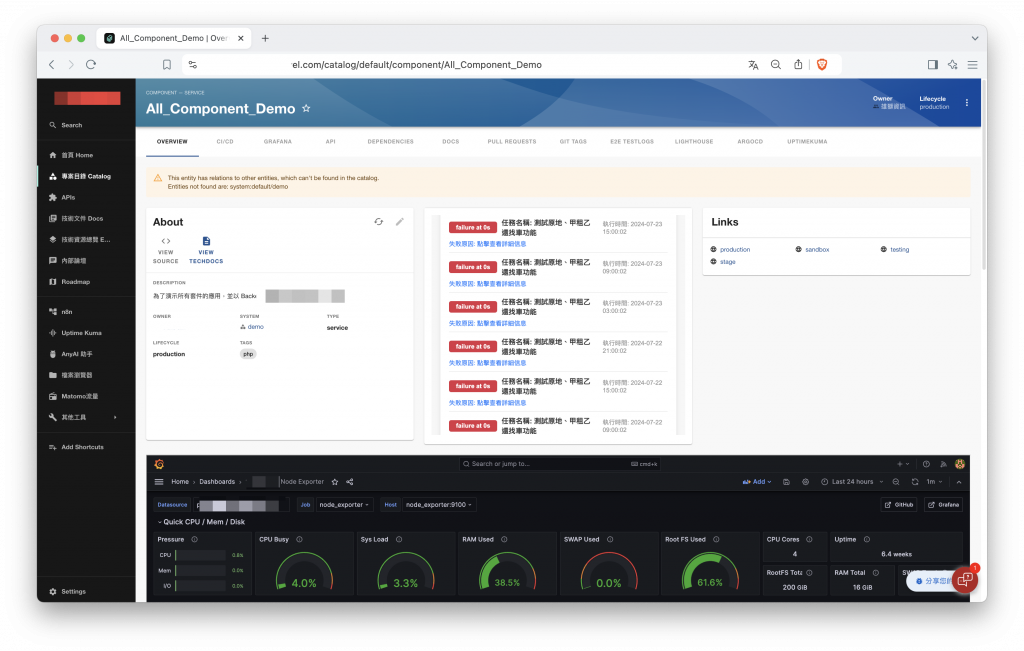
本文演示了如何透過 Grafana 與 Prometheus 將監控儀表板整合到 Backstage,為 Backstage 增添動態觀察服務狀態的能力。借助 Grafana 靈活的儀表板功能,我們可以間接整合其他服務的資訊,而無需直接整合到 Backstage。例如前面提到的,Grafana 支援顯示 Uptime Kuma 的數據,也許我們就不必為其撰寫專屬的前端插件來做整合。個人認為這個組合是 Backstage 不可獲缺的搭配之一。
https://ithelp.ithome.com.tw/articles/10332031
https://doubletapp.medium.com/overview-of-monitoring-system-with-prometheus-and-grafana-9ce6501eff88
https://github.com/880831ian/Prometheus-Grafana-Docker
https://github.com/prometheus/node_exporter
https://medium.com/@faulycoelho/net-8-api-with-prometheus-and-grafana-29003adafd43
https://github.com/K-Phoen/backstage-plugin-grafana/tree/main

 iThome鐵人賽
iThome鐵人賽